Jiayang Li (李佳阳) Undergraduate Education | Internship | Research Interest | Projects | Honors Faculty of Computing, Harbin Institute of Technology Email: lijiayang.cs@gmail.com (prior); lijiayang@stu.hit.edu.cn [GitHub] [Google Scholar]
TIP-2025
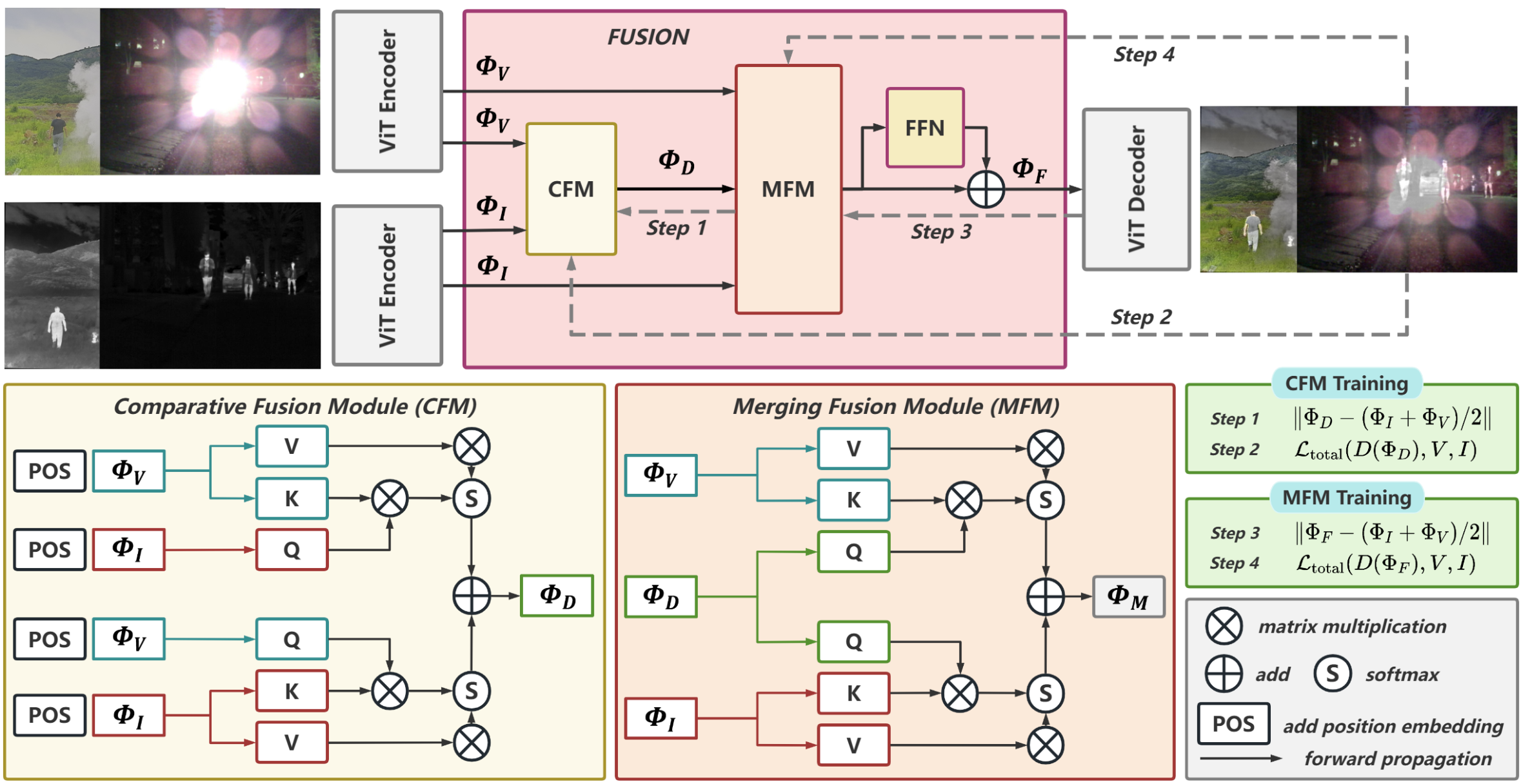
MaeFuse: Transferring Omni Features with Pretrained Masked Autoencoders for Infrared and Visible Image Fusion via Guided Training. Jiayang Li, Junjun Jiang, Pengwei Liang, Jiayi Ma, Liqiang Nie
[code] [pdf]